
5 years of data processing: Lessons learned
During my thesis work, I had to process lots of data. Many meshes I worked on contained hundreds of millions of triangles, and the intermediate and generated outputs would typically range in the tens to hundreds of GiB. All of this means that I had to spend a significant amount of time on “infrastructure” code to ensure that data processing remained fast, reliable and robust.
My work also required me to create many different tools for specific tasks. Over the years, this led to additional challenges in the area of tool creation and tool discovery. In this blog post, I’ll take a look at the evolution of my tool infrastructure over roughly five years, and the lessons I learned.
Processing overview
Data processing includes tasks like converting large data sets into more useful formats, cleaning up or extracting data, generate new data and finally modify data. We can group the tools into two broad categories. The first category reads an input and generates an output, while the second mutates the existing data in some way. A typical example for category one is a mesh converter; for category two, think for instance of a tool which computes smooth vertex normals.
Why is it important to make that distinction? Well, in the early days, I did have two kinds of tools. Those in the second category would typically read and write the same file, while those in the first category had well defined inputs and outputs. The idea was that tools which fall into the second category would wind up being more efficient by working in-place. For instance, a tool which computes a level-of-detail simplification of a voxel mesh simply added the level-of-detail data into the original file (as the tool which consumed the data would eventually expect everything to be in a single file.)
Mutating data
Having tools which mutate files lead to all sorts of problems. The main problem I ran into was the inability to chain tools, and the fact that I would often have to regenerate files to undo the mutation. Point in case, the level-of-detail routine would sometimes create wrong blocks, and those can’t be easily fixed by re-running the tool with a special “replace” flag. Instead, I had to wipe all level-of-detail data first, followed by re-rerunning the tool again. And that was after I had fixed all bugs which would damage or replace the source data.
Towards functional tools
Over the years, I refactored and rewrote all tools to be side-effect free. That is, they have read-only input data and write one or more outputs. Turns out, this made one optimization mandatory for all file-formats I used: The ability for seek-free, or at least seek-minimal reading. As I mentioned before, the original reason for mutating data in-place was performance. By writing into the same file, I could avoid having to copy over data which was taking a long time for the large data sets I had to work with.
The way I solved this was to ensure that all file formats could be read and written with near-perfect streaming access patterns. Rewriting a file would then be just as fast as copying, and also made processing faster in many cases, to the point that “in-place” mutation was no longer worth it. The biggest offender was the level-of-detail creation, which previously wrote into the same file. Now, it wrote the level-of-detail data into a separate file, and if I wanted to have them all together again, I had to merge them which was only practical once the read/write speed was close to peak disk I/O rates.
At the end, the changes to the file formats to make them “stream-aware” turned out to be quite small. For some things like the geometry streams, they were streams to start with, and for the voxel storage which was basically a filesystem-in-a-file all functions were modified to return entries in disk-offset order. For many clients, this change was totally transparent and immediately improved throughput close to theoretical limits.
Tool creation & discovery
After several years, a big problem I ran into was tool discovery. I had dozens of command-line tools, with several commands each and with lots of command-line options. Figuring out which ones I had and how to use them became an increasingly complicated memory-game. It also increased the time until other users would become productive with the framework as tools were scattered around in the code base. I tried to document them in my framework documentation, but that documentation would rarely match the actual tool. The key issue was that the documentation was in a separate file.
Similarly, creating a new tool would mean to create a new project, add a new command, parse the command-line and call a bunch of functions. Those functions were in the tool binary and could not be easily reused. Moving them over to libraries wasn’t an option either, as these functions were typical library consumers and very high-level. And finally, even if I had them all as functions in a library, I would still need a way to find them.
The solution was to implement a new way for tool creation which also solved the tool discovery problem. This turned out to be an exercise in infrastructure work. The key problem was to balance the amount of overhead such that the creation of a tool doesn’t become too complicated, but I still get the benefits from the infrastructure.
What I ended up with was levering a lot of my framework’s “high-level” object classes, run-time reflection and least-overhead coding. Let’s look at the ingredients one-by-one: In my framework, there’s a notion of an IObject quite similar to Java or C#, with boxing/unboxing of primitive types. If I could somehow manage to restructure all tool inputs & outputs to fit into the object class hierarchy, this would have allowed me to use all of the reflection I already had in place. Turns out that because the tools are called infrequently, and because inputs are typically files, strings, numbers or arrays, moving this into a class-based, reflection-friendly approach wasn’t too hard.
Now I just had to solve the problem how to make a tool easy to discover. For each tool, I need to store some documentation along it. Storing the tool description and documentation separately turned out to be a fail. The solution I ended up with was to embed the declarative part as SJSON right into the source file.
Let’s take a look at a full source file for a tool which calls a vertex-cache index optimizer for a chunk:
#include "OptimizeIndices.h"
#include "niven.Geometry.VertexCacheOptimizer.h"
namespace niven {
///////////////////////////////////////////////////////////////////////////////
struct OptimizeIndicesProcessor final : public IGeometryStreamProcessor
{
OptimizeIndicesProcessor ()
{
}
private:
bool ProcessChunkImpl (const GeometryStream::Chunk& input,
GeometryStream::Chunk& output) const
{
if (input.GetInfo ().HasIndices ()) {
const int indexCount = input.GetInfo ().GetIndexCount ();
HeapArray<int32> indices (indexCount);
std::copy (
input.GetIndexDataArrayRef ().begin (),
input.GetIndexDataArrayRef ().end (),
indices.Get ());
Geometry::OptimizeVertexCache (MutableArrayRef<int32> (indices));
output = input;
output.SetIndexData (indices);
} else {
output = input;
}
return true;
}
};
/**
================================================================================
name = "OptimizeIndices",
flags = ["None"],
ui = {
name = "Optimize indices",
description =
[=[# Optimize indices
Optimizes the indices of an indexed mesh for better vertex cache usage. The input mesh must be already indexed.]=]
},
inputs = {
"Input" = {
type = "Stream",
ui = {
name = "Input file",
description = "Input file."
}
},
"Threads" = {
type = "Int"
ui = {
name = "Threads"
description = "Number of threads to use for processing."
}
default = 1
}
},
outputs = {
"Output" = {
type = "Stream",
ui = {
name = "Output file",
description = "Output file."
}
}
}
================================================================================
*/
/////////////////////////////////////////////////////////////////////////////
bool OptimizeIndices::ProcessImpl (const Build::ItemContainer& input,
Build::ItemContainer& output,
Build::IBuildContext& context)
{
const OptimizeIndicesProcessor processor;
return ProcessGeometryStream (input, output, processor, context);
}
} // namespace niven
There’s a tiny boilerplate header for this which declares the methods, but otherwise it’s empty. What do we notice? First, all inputs & outputs are specified right next to the source code using them. In this case, the ProcessGeometryStream method will fetch the input and output streams from the input and output container. All of this is type safe as the declarative types are converted into types used within my framework, and all queries specify the exact type.
It would be also possible to auto-generate a class which fetches the inputs and casts them into the right type, but that never became enough of a problem. This setup – with the integrated documentation and code – is what I call “least-overhead” coding. Sure, there is still some overhead to set up a build tool which slightly exceeds the amount of code for a command line tool which parses parameters directly, but the overhead is extremely small – some declarative structure and that’s it. In fact, some tools became smaller because the code to load files into streams and error handling was now handled by the build tool framework.
One interesting tid-bit is that the tool specifies an IStream – not a concrete implementation. This means I can use for instance a memory-backed stream if I compose tools, or read/write to files if the tool is started stand-alone. Previously, the command line tools could be only composed through files, if at all.
On the other hand, I get the benefits of a common infrastructure. For instance, tool discovery is now easily possible in different formats:
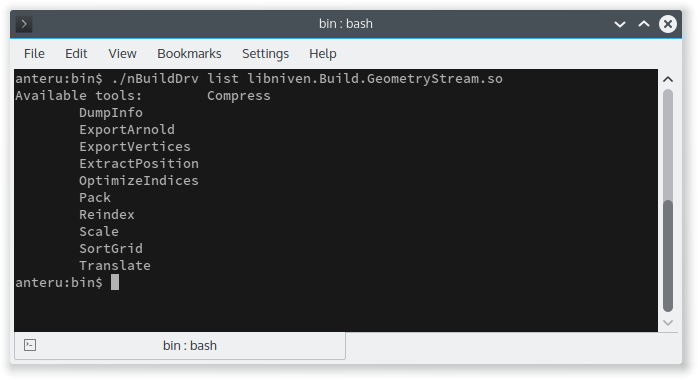
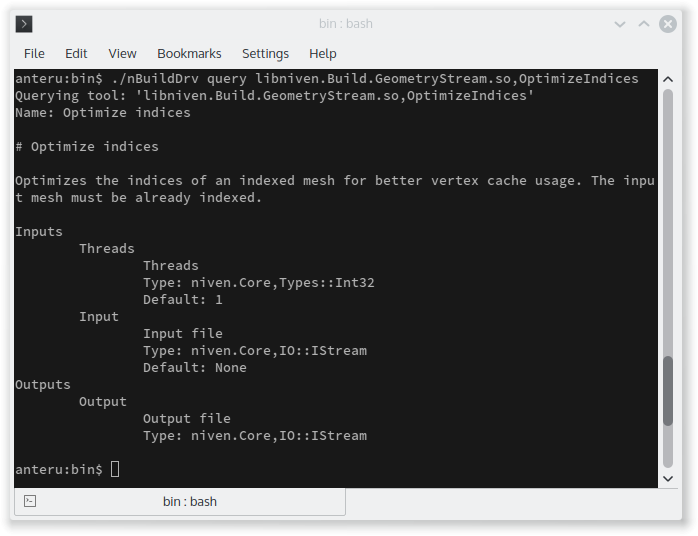

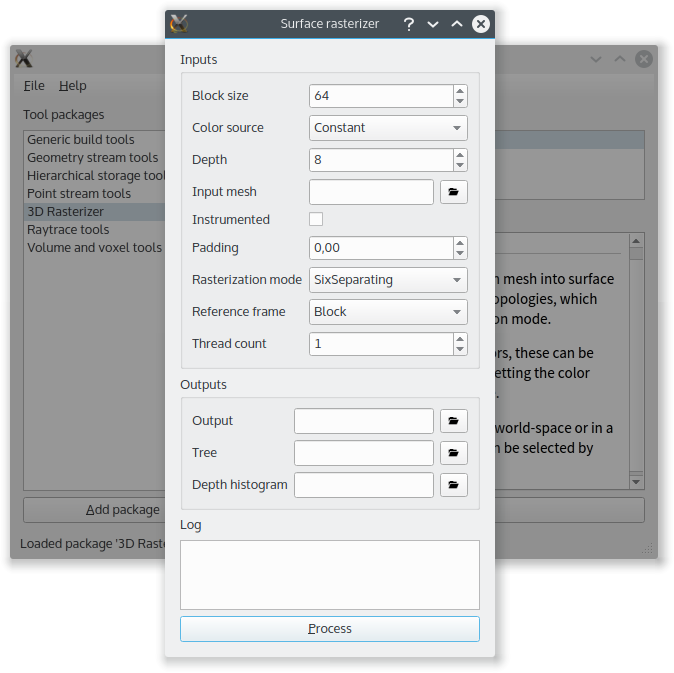
Conclusion
In hindsight, all of this looks quite obvious – which is good, as it means the new system is easy to explain. However, during development, all of this was a long evolutionary process. At the beginning, I was trying to keep it simple as much as possible, with as few library, executables and boilerplate as possible. Over time, other parts of the framework also evolved (in particular, the boxing of primitive types which integrated them into the common class hierarchy came pretty late) which affected design decisions. Towards the end, I was also taking more and more advantage of the fact that the code was an integral part of my framework.
By tying it closer to the rest of the code base I could drastically cut down the special-case code in the tool library and reap lots of benefits. The downside is that extracting a tool from the framework is now very hard and will require a lot of work. This is the key tradeoff – going “all-in” on a framework may mean you have to live inside it. If done correctly, you can get a lot out of this, and I’m leaning more and more towards more infrastructure on projects. Good infrastructure to “plug” into is where large frameworks like Qt or Unreal Engine 4 shine, even if at the beginning, this means there is a steeper learning curve and more overhead. The key in such an evolution is to strive for the simple and obvious though and not introduce complexity for its own sake.
The other key decision – to move towards state-less, functional building blocks – turned out to be another big winner in the end. The disadvantages in terms of disk usage and sometimes I/O time were more than offset by testability, robustness and the ability to compose full processing pipelines with ease.