
Introducing kyla 2.0
One year passed and I’ve been using kyla quite a bit for my personal projects. As it turns out, it still looks like I need to write everything three times before it works properly. Even though it’s 2.0, it’s actually the third major update of kyla, as there has been one rewrite before 1.0 happened.
So what happened? The original goals I’ve set for kyla still remained, but while trying to re-introduce encryption, I’ve ran into a couple of design issues which resulted in more and more ugly code. At the same time, the database scheme turned out to not be as forward-looking as I thought it would be, so that had to be updated as well. Finally, kyla 1.0 only shipped with a very basic UI, and for kyla 2.0 I’ve revamped the default UI significantly to make it possible to just ship with it instead of having to write your own.
Introducing 2.0
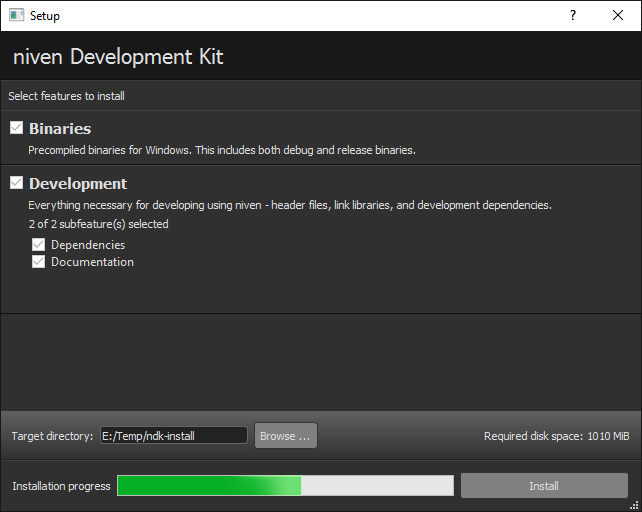
A lot of things changed for 2.0 – check out the changelog for details. All of this has been driven by my primary use case, which is deploying the ndk. The ndk is the SDK for my home framework, and consists of roughly 15.000 files, totaling 1 GiB of data.
The biggest change is probably the updated database scheme. It should be easy to extend now, and has proper layering. At the core, we still have the features, but the association to file contents is more loose. Eventually, adding shortcuts for instance should be possible, unlike in the previous revision which was very much hard-coded to be content-only.
The second part is the UI - it’s completely redone to allow a feature tree, that is, nested features, and provides a much more polished experience. UI information is provided in a separate layer and is not deployed. This means that once installed, you still have to use the feature ids just as in kyla 1.0, but as long as the source repository is present, the UI will remain available for configuration, updates and downgrades.
The future
For me, kyla 2.0 solves all my problems in a much more robust way than kyla 1.0 could. In particular, the new UI is something I can ship to people. I’ve also implemented various under-the-hood performance improvements so it’s no longer doing really embarrassing things :).
Will there be future updates? Maybe. At the moment, it just works, so there’s no need to fix things, but I’ll look into issues as I run into them, just as I rewrote kyla once I’ve hit some roadblocks with 1.0. Just make sure to tell me in case you run into an issue. As before, you can find the source code both on github.com/anteru and Github. Enjoy!