
Introducing kyla - part 2
Today we’re going to look at the current state of kyla, what’s in the box and what’s missing.
What do we have here?
kyla as of today has everything you need to get started – some documentation, a sample user interface written using Qt, the repository generator, and a sample installation to play around it. All of it is written with some C++ 11 flavor which happens to compile on Visual Studio 2015 Update 3 and recent GCC/Clang. I haven’t bothered trying older compilers – the interface itself is plain C and should work with any language. Overall, I’d estimate I’ve spent well over a hundred hours on this, but the project is still rather small and is comprised of just 5750 lines of code.
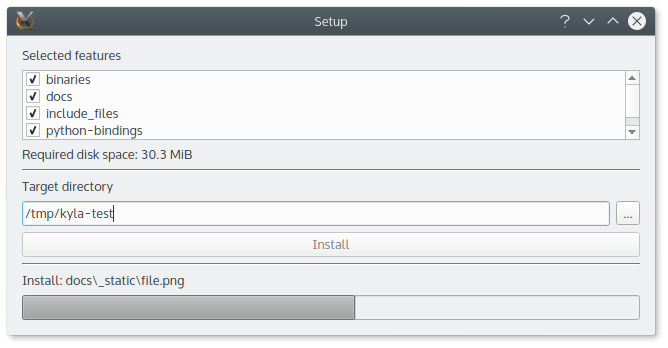
Does it work? If you need what I need – a simple way to dump an application onto a server and allow someone to install parts of it selectively, then yes, it does work. It’s better than just a ZIP package because the user can select what to pick, and it allows for easy updating which is really helpful if most of your application doesn’t change between releases.
So what’s missing?
Is kyla production ready? No, not yet. It does work in the “general” case but it’s not as robust as it could be. Error handling is rather minimal, but the hooks and entry points are all there. Same goes for progress reporting – right now, only configure reports an useful progress but everything necessary is in place. The Linux side needs some more love as the web installer is not functional there.
Other than that, the biggest item that’s missing is better patch handling. Everything necessary is in place, but a tool to remove contents to create a patch repository hasn’t been written. In addition, patching of files is something that fits very nicely into the current design but hasn’t been implemented. The basic idea is to introduce a new concept, called “transformation”, which can transform one content object into another. For a patch, the installer first identifies the missing contents, and then tries to transform existing content using a transformation. This would allow binary diffs and other things to cut down the patch size even more.
And there’s a lot of small things that would be nice to have. More compression algorithms, smarter handling of small files, cancel/resume during an installation, and more.
You might think there’s more missing than implemented – but if you take a closer look, what you get today does solve the problem I’ve set out to solve when I started the project. If you want to know if it’s enough for you, why not give it a shot: Grab the source from either github.com/anteru or Github and try it out!
What’s next?
My hope is that you, dear reader, will find this project useful, either to take a look at the solutions developed in there, or because some of the code looks interesting for you. Of course, I’d be most delighted if you’d actually use kyla in production for what it was designed for, and report issues, request features or submit pull requests. From my side, I’m happy with where I got: It solves the problems I wanted it to solve so I’ll only touch it if I run into a bug affecting me, but otherwise, there’s nothing on my list that’s missing right now. But I don’t know what you need and I’m really curious to see how it will evolve!